
What are we solving for with copper-rs?
Robotics demos have been impressive for a long time.
Humanoid robots dancing.
Quadrupeds doing parkour.
Drones flying complex trajectories.
Robots manipulating objects with increasing dexterity.
At the same time, machine learning has advanced rapidly. Perception systems that were considered difficult ten years ago are now common.
Note: This blog entry is based on the small keynote I gave at our copper-rs meetup, you can also check it out on our youtube channel
“Given all of this progress, a simple question naturally appears: But where are the robots?”
We are not talking about research prototypes or lab demonstrations but autonomous systems operating reliably in the real world.
Today the most visible example is probably Waymo. It represents one of the most advanced deployments of autonomy and required enormous investment in sensors, infrastructure, and engineering effort.
Even then, the economics remain difficult. Autonomy at scale is still extremely challenging.
The gap between impressive research demonstrations and reliable autonomous products is much larger than it appears from the outside. Copper started from the desire to understand where that gap comes from.
Robotics Works in Controlled Conditions
Most robotics projects follow a similar trajectory.
Early development tends to move quickly. A robot learns to navigate a hallway, follow a road, or operate inside a structured environment such as a warehouse.
These early results are often good enough to produce convincing demonstrations. They show that the core approach works and that the system can perform useful tasks.
However, the real challenge begins once the robot leaves controlled conditions.
Robots deployed in the real world encounter environments that are fundamentally unpredictable. Lighting conditions change, sensors occasionally misbehave, and unexpected situations appear that were never part of the initial design.
This shift fundamentally changes the development process.
The Long Tail Problem
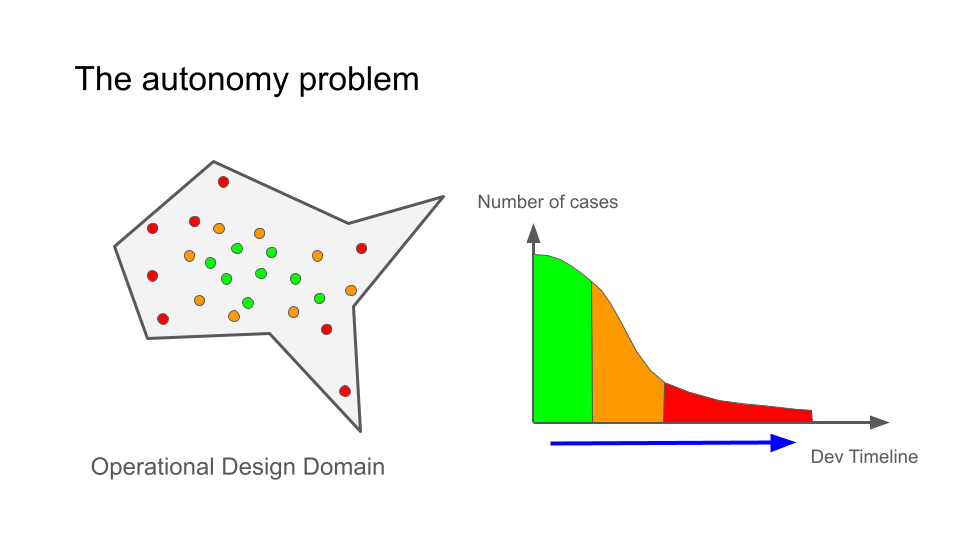
Autonomy development is dominated by what is commonly called the long tail.
Many situations a robot encounters are common and easy to handle. A car driving down an empty road or a robot navigating a clear corridor represents the majority of operating time.
Operational Design Domain / Long Tail graph
But safe autonomy requires handling far more than common cases. It must also handle rare events that occur only occasionally.
Examples include unusual lighting conditions, sensor edge cases, unexpected obstacles, or combinations of circumstances that were never seen during initial testing.
As development progresses, improvements become harder because each new issue tends to correspond to increasingly rare situations. Collecting the relevant data becomes more expensive and reproducing failures becomes more difficult.
Eventually progress slows dramatically because the engineering loop breaks down. Failures happen rarely and inconsistently, which makes them extremely difficult to analyze and fix.
Closing this loop requires the ability to reproduce failures reliably.
Determinism as a First Principle
Reproducing failures in robotics systems is harder than it should be.
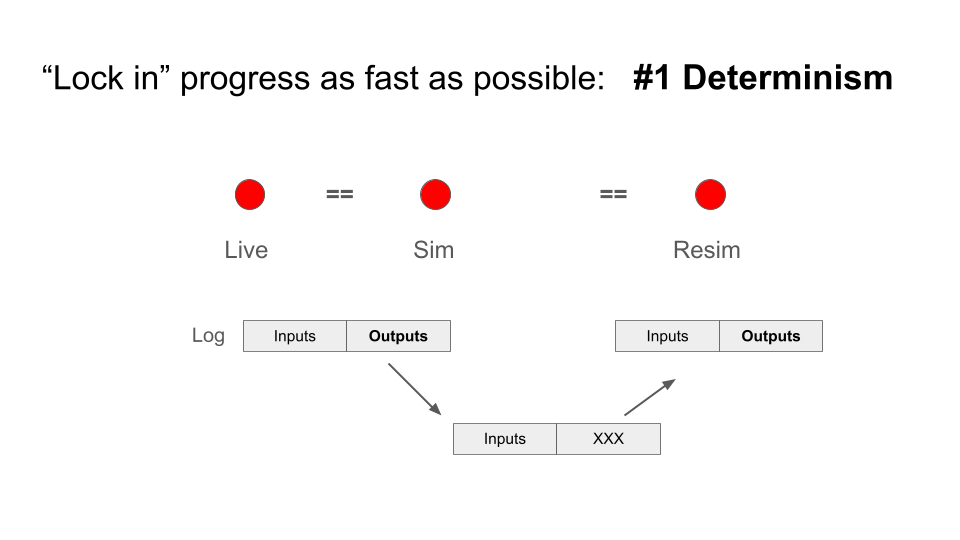
Ideally, debugging a failure would follow a simple workflow. A robot run is recorded, the relevant inputs are captured, and the system is replayed offline in order to reproduce the exact same behavior.
In practice this often fails because robotics software stacks are not deterministic. Small sources of nondeterminism accumulate throughout the system: thread scheduling, asynchronous messaging, operating system behavior, memory allocation patterns, and timing variations.
When these effects interact, the same inputs can produce slightly different outputs on every run. This makes debugging extremely difficult because a failure that appears once may never appear again under identical conditions.
Deterministic replay slide: Outputs on Resim are exactly the same as the outputs on Live or Sim
Copper was designed around the idea that deterministic replay should be a fundamental property of the system. Given the same inputs, the system must produce exactly the same outputs. This guarantee allows failures observed in the field to be reproduced reliably during development.
In Copper this property is continuously tested. Recorded runs are replayed automatically and the resulting outputs are compared against the original execution. Any divergence indicates that determinism has been broken somewhere in the system.
This constraint strongly influences the rest of the design.
Performance Without Sacrificing Modularity
Autonomous systems operate in a tight control loop that continuously processes sensor data and generates actions.
The latency of this loop directly affects how the robot behaves. Faster loops allow the system to react more quickly to environmental changes.
Unfortunately many robotics frameworks introduce significant overhead through serialization, message passing layers, buffering, and dynamic scheduling.
Developers frequently respond by merging multiple components together into large processing blocks. Doing so reduces communication overhead but also eliminates many advantages of modular systems. Debugging becomes harder and reusable components become scarce.
Copper approaches the problem differently. The runtime is designed so that the cost of decomposing a system into small components remains extremely low. This makes it possible to preserve modularity without sacrificing performance.
Maintaining small components has several benefits. Individual stages can be inspected independently, intermediate data can be logged for debugging, and components become reusable across projects.
These properties become particularly valuable when diagnosing failures in the long tail.
Modern Computers Are Not Optimized for Robotics
Are the modern computers that are AI capable the best platforms for robotics?
Another challenge arises from the hardware itself.
Modern CPUs are complex parallel machines designed to maximize throughput across many tasks. They rely on deep cache hierarchies, speculative execution, and multiple cores to achieve high performance.
This architecture works well for workloads such as web servers or video streaming, where throughput matters more than predictable latency.
Robotics systems have different requirements. A robot must process sensor data and react within predictable time bounds. Small variations in execution timing can accumulate and degrade system behavior.
Bridging the gap between hardware optimized for throughput and software that requires low latency requires careful control over memory access patterns and scheduling.
Copper attempts to align software execution with the underlying hardware architecture rather than fighting against it.
Navigating Design Tradeoffs
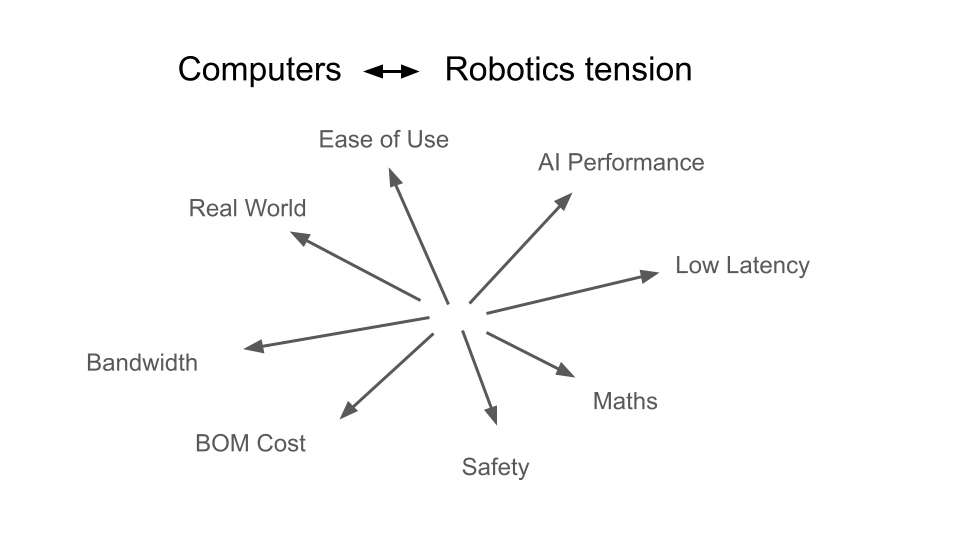
Designing a runtime for robotics involves balancing several competing constraints.
Low latency and high throughput do not always align. Hardware optimized for bandwidth can introduce unpredictable delays.
The design tradeoff for a robot is complex as a lot of things you need are in a constant tug of war
Algorithm designers prefer abstract representations of computation, while efficient execution requires awareness of hardware details such as memory layout and caching behavior.
Safety considerations push systems toward static guarantees, while experimentation during development requires flexibility.
Finally, increasing AI capability often requires more compute resources, which increases cost and power consumption in deployed robots.
Copper was designed by explicitly acknowledging these tensions and choosing design points that favor reliability and reproducibility.
Copper as Compiler, Operating System, and Runtime
The resulting system does not fit neatly into a single category.

Copper is 3 things at the same time
Copper behaves simultaneously as a compiler, an operating system, and a runtime for compute graphs.
The compiler component moves as much work as possible out of runtime and into compile time. Tasks such as scheduling decisions and memory layout can be resolved before the robot ever executes the program.
Treating Copper as an operating system allows the runtime to avoid many behaviors of general-purpose operating systems that introduce unpredictable timing, such as virtual memory and dynamic scheduling.
Finally, Copper provides a safe compute graph abstraction that allows robotics algorithms to be expressed naturally while maintaining strong safety guarantees.
Rust plays a central role here because it provides memory safety and predictable performance without introducing hidden runtime costs.
Generating a Specialized Runtime
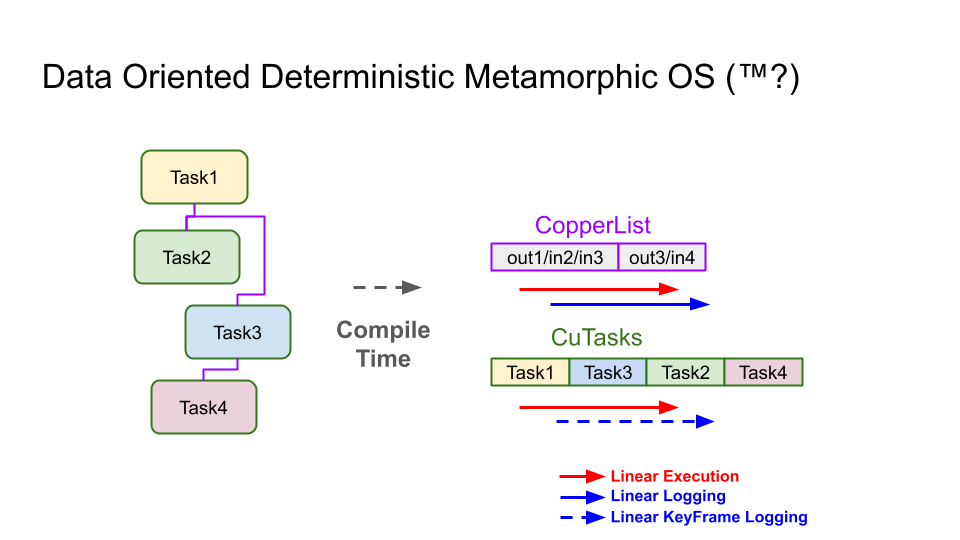
Everything is executed in a linear fashion in Copper
When a robotics application is compiled with Copper, the system analyzes the graph of tasks that define the robot’s behavior.
From this graph it generates a specialized execution plan and memory layout tailored to that particular application.
The tasks are ordered in memory so that execution follows a predictable sequence. Memory buffers used to pass data between tasks are laid out sequentially, improving cache locality and reducing latency.
This approach turns the pipeline into a highly efficient execution path aligned with the behavior of the processor’s cache and prefetch systems.
Real-Time Execution and Logging
Copper separates two concerns during execution.
The real-time loop processes sensor data and produces actuation outputs as quickly as possible. This path avoids unnecessary work and keeps latency low.
A secondary process handles logging and data persistence. Logging occurs between cycles so that it does not interfere with the real-time loop.
Occasionally the system records keyframes that capture internal state. These keyframes allow debugging tools to jump directly into a replay without requiring the entire execution history from the beginning of the log.
This mechanism helps maintain deterministic replay even when logs are incomplete or partially corrupted.
Toward Reliable Autonomy
Robotics will not become widespread simply because algorithms improve.
Reliable autonomy requires infrastructure that allows engineers to reproduce failures, understand system behavior, and iterate quickly on real-world deployments.
Copper explores one possible approach to this problem by combining deterministic replay, compile-time system generation, and data-oriented execution.
The project is open source and actively evolving as more real systems adopt it.